|
ELLES
English Language Lexical Expert System
Scott Shipp, Brant Watrous
Dr. George Hauser, advisor
May 17, 2002
Pacific Lutheran University Department of
Computer Science and Computer Engineering
Abstract
This project is an inferencing engine that solves proofs relating to word relationships in the English language. Using a lexical reference system known as WordNet™, the system refers to a knowledge base of assertions about how words are most commonly used together and answers queries about relationships between objects and actions, or between objects and other objects. This is accomplished by giving the system rules and facts about English noun and verb use and simple word definitions (to build on to). The system stores word relationships as logical assertions that can then be used in inferencing. Based on assertions in its database, it answers queries to the best of its ability.
Contents
- Introduction
- Performance Specifications
- Object Model
- Data Model
- Shell Application
- Logikus Class Modifications
- Lexical Knowledge Base Interface
- WordNet™ and JWordnet Utility
- Local Knowledge Base
- Query Analysis Algorithm
- Design Methodology
- Results
- Cost Analysis
- Conclusions
- Recommendations
- Works Cited
- Appendices
- Appendix A - Glossary of Terms
- Appendix B - Lexical Relationship Definitions
- Appendix C - System rule types
- Appendix D - System fact types
List of Figures
- Component Interaction Diagram
- Modified Logikus IDE Application
- Sequence Diagram
- UML for Database Class
- Initial Component Diagram
- Second Component Diagram with Output Dictionary
- An Early Example of the XML Markup Language
- Third Component Diagram
- Final Component Diagram
List of Tables
- Classes corresponding to Components in Figure 1
- List of Implemented Predicates
- Important Classes of ELLES
- Example JWordnet Functions
- Query syntax
- Introduction
Traditionally, inferencing engines are built by entering every assertion (true statement) by hand directly into the system. Our inferencing engine is designed to gather as much information as it can, using a lexical reference system called WordNet™ to induce probable assertions. Since the engine is able to create assertions based on the information it finds in WordNet™, it does not have to rely on user input alone. However, accuracy in the data is more difficult to maintain than if a user entered it. The assertions it produces from the dictionary are stored in memory for use in logical analysis of a user's query (or goal) statement. For our purposes, this statement can be read as an interrogative statement to the system. The ultimate goal for this database is to understand and answer human input more effectively than traditional rules-based systems. The idea is that if the inferencing engine doesn’t have a rule that applies directly to a question asked it, it can read the dictionary to try and fill in the blanks.
The tools used to implement this inferencing engine were Java, Logikus (an open source logic language), and WordNet™, the lexical reference system. WordNet™ is a lexical database developed by the cognitive science laboratory at Princeton University and provides lexical information not found in other dictionaries. There is an interface for WordNet™ called JWordnet that we used to bridge the divide between WordNet's source files and our application. WordNet™ is accessible via the web at http://www.cogsci.princeton.edu/~wn/, though it can also be kept on a local computer as well.
Logikus and its integrated development environment were developed by Steven J. Metsker. Metsker authored a book called Building Parsers with Java that comes with a large amount of source code. His IDE application had the ability to carry out logic-engine functions that our project needed, as well as a user interface that was already constructed. The application associated with our project is a modified version of his IDE application.
- Performance Specifications
2. 1 Object Model
The English Language Lexical Expert System (ELLES) follows the model of an expert system (one type of AI construction), meaning that it should have heuristics, a database, a user-friendly interface, and an inferencing engine [5]. There are also versions of this model that include an explanation subsystem for giving to the user the why's and how's of the logical conclusions made by the system. A knowledge base editor is another component commonly added to an expert system. We hope to implement both of these additions at a later time using the XML standard. Our system also lacks a generally user-friendly interface at this point. These things are still long-term goals, as is adding additional knowledge sources such as Cyc® and online dictionaries.
We did, however, complete the most important aspects of the system, as it is currently designed. This is shown below in an overall component interaction diagram. Those parts which are shaded are those that are currently implemented:
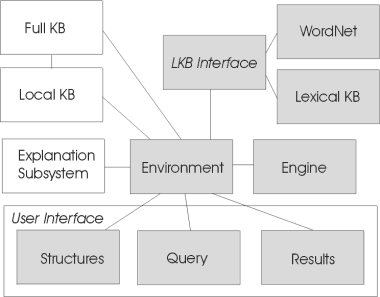
Fig. 1. Component Interaction Diagram
The database component of an expert system is often referred to as a knowledge base, to which the letters KB refer. The LKB Interface stands for Lexical Knowledge base Interface. This interface provides abstraction for the two data storage units on the diagram as well as for others that could be added later. A common set of functions searches and retrieves data from all sources of data. The WordNet component is not WordNet™ itself, but a wrapper object that retrieves requested data from WordNet™. One other clarification about the diagram: Structures are the statements of a Logikus program, a concept that will be covered later in the Data Model.
At the abstraction level of this diagram, the various components and their relation to the system are quite clear. Later these component names will be replaced by the class names they represent. The Environment component orchestrates and relays data to all other parts of the system. The user interface consists of two INPUT fields, Structures (or Program) and Query, and one OUTPUT field, Output. These correspond to the text areas of the same names on the shell application (see Table 2). Originally, the Structures--local sets of rules and facts entered by the user--were to be stored in the Local Knowledge Base, and more universal data--entered by the system administrators--would be kept in the Full Knowledge base. This organization of data might be implemented later. At this point, All local Structures come directly from the user (or from a text file) and there is a static class called Semantics that holds the universal rules of the system. Data organization, as it is implemented, is described with detail in the next section.
Because the Environment object had so many tasks associated with it, we decided to break it into two parts, one part to be associated with the Engine and the other with the LKB Interface. Later we associated the terms QueryAnalysis (section 2.5) and Database (section 2.6) with these two parts, respectively. From an object oriented analysis of our component diagram, a list of necessary objects was created. These are:
| User Interface |
Environment (2 parts) |
Engine |
| LKB Interface |
WordNet |
Lexical KB |
Rather than build each of the objects needed for our system, we looked for components (coded in Java) that had already been developed, in order to reduce our development time. We found source code for several of these components in the book Building Parsers in Java by Steven J. Metsker. He developed an open source application, an Integrated Development Environment (IDE), for a logic language that he wrote called Logikus. Logikus is based on Prolog and he developed the application in order to demonstrate its parsing capability. As well as parsing the input, however, the application also functioned as a logic engine. Logic languages are not compiled and so they can easily be written and executed from the same environment.
With a modified version of his User Interface and Engine, two of our components were already taken care of and only four remained to be implemented. From this point, however, it became difficult to keep objects as separate entities within the code. Only three objects themselves became Java classes: the LKB Interface, WordNet, and the Lexical KB, and the LKB Interface is an abstract class--WordNet and Lexical KB (which we now call LocalDatabase) both implement it. The Database side of the Environment also became a Java class, while the QueryAnalysis side was implemented within a pre-existing class of the Logikus application. The class names now associated with the objects list are shown in Table 1 below. The specific functionality of these classes is discussed in sections 2.4 through 2.8:
| Object |
Class |
Object |
Class |
| User Interface |
LogikusIDE.java |
LKB Interface |
DataStore.java |
| Engine |
several classes |
WordNet |
Wordnet.java |
| QueryAnalysis |
part of LogikusMediator |
Lexical KB |
LocalDatabase.java |
| Database |
Database.java |
|
Table 1. Classes corresponding to the components of Fig. 1
2.2 Data Model
To understand the design of our system, some background knowledge in logic programming is needed. Data in a logic language must be thought of differently than data in an imperative language. Logic programs are written using structures. Generally, a structure takes the basic form:
predicate(term1, term2);
but they can also grow more complex using lists, arithmetic expressions, and so forth. The terms of a structure can be structures themselves. Every piece of a programming language, and therefore of Logikus, is a structure. Structures can be unified by the language's engine to solve proofs or query data [2]. Data in a logic language is also composed of structures, and that is the concept we will focus on in this section. Likewise, any data source in a logic system must return structures instead of raw data.
The word relationship data in our system, like all data in a logic system, must appear in the form of an axiom. An axiom is either a fact structure or a rule structure. Fact structures claim a true relationship between their terms, and each of their terms must also be Facts. Rule structures are a set of structures with one structure serving as the head (this term is used because in logic, rules are referred to as headed-Horn clauses). The other "tail" structures imply the head. The head is true if all the tail structures are true. Rules are used to give the logic to logic programs [2].
We had this preliminary design for our database: lexical information would be stored in two locations, WordNet™ installed locally, and our database. The two will share a common interface so that data from both sources comes into the system in the same form. Every predicate (or functor) in our system indicates a lexical modifier that creates a relationship among a set of word senses. Words have both an appearance and a meaning, and the sense of a word refers to its meaning (sense is a term we borrowed from WordNet™). The string that denotes a word is called a lemma. Figure 2 denotes the set of lexical modifiers we hope to give our system and Appendix D gives their specifications.
| Fact Type Predicates |
Inverse Fact Types |
Rule Type Predicates |
| synonym |
-- |
syn |
| hypernym |
hyponym |
isa |
| meronym |
holonym |
hasa |
| holonym |
meronym |
does |
| has_ability |
has_agent |
does_to |
| has_object |
has_action |
case |
Table 2. List of Implemented Predicates
Included in this set are the six lexical relationships that have been implemented: synonymy, hypernymy, meronymy, holonymy, and the verb-specific relationships "has ability" (X has the ability to Y) and "has action," where a verb X has a likely direct object Y. An axiom built with one of these functors is a fact in our system and contains two or more lemmas as attributes. An example is:
has_ability(band, play);
This fact, if found in our database or in data provided by WordNet™, will tell us if any sense (definition) of the word band has the ability play. We know two additional truths about the sense of play used here: it is a verb (we know this by the specifications of the has_ability functor), and we know that the verb's transitivity is left undefined. Verb transitivity in our system is specified using the functor has_object. In this case, the fact
has_object(play, song);
would complete the transitivity of the verb play. For our system to be more accurate, each word lemma should have a sense number to set it apart from all other senses with the same lemma. This capability is not fully implemented, but for the rest of this paper a tilda and pound sign (~#) will be used to indicate when a specific sense of a word is anticipated, rather than simply its lemma. Determining the sense of words requires a larger set of tools for analyzing their context and frequency.
Finally, an axiom source is just what it seems, a source from which the Logikus engine receives axioms. Logikus only implemented one type of axiom source, called a program. A program is written inside the application by the user. We came to a realization at some point in our design process that a great deal of our work would involve adding a new axiom source, an external axiom source, to Logikus. Our LKB Interface (now DataStore) matched this function perfectly. Section 2.6 describes how the Database class works as an axiom source by calling external data through the DataStore interface.
2.3 Shell application
The Logikus IDE written by Steven J. Metsker consists of a set of application classes that import a great deal of functionality from a package he named engine and parse. Java.Swing is used for the frame, text areas, and buttons. The Program, Query, and Output text areas are modifiable by the user. The Database area is new to our modified version of his application, and is not accessible by the user. The Next button returns the next unification with the query, while the All button returns all unification results at once. There is a Halt button to stop the thread if a loop occurs. The Clear Program button clears the Program, Query, and Database text areas, and the Clear Output button resets the Output area. This is a screen shot of the modified Logikus IDE application:

Fig. 2 - Modified Logikus IDE Application
As it was originally developed, a user entered logical structures (in a language similar to Prolog) into two text areas of the Logikus IDE. Structures in the first two, Program and Query, were matched using a process called unification and the results are displayed in the Output text area. In this way, a user could write a program in Logikus, and enter data which that program refers to, and then search through that data for some certain behavior using a query (sometimes called a goal statement). This is the process used in conducting proofs as well. A set of axioms is entered into a Program, and the goal statement is that statement the user wishes to prove.
2. 4 Logikus Class Modifications
As was mentioned above, the implementation of our object model required that some of the Logikus IDE classes be modified, some left, and others added from scratch. In the table below, classes in bold type are those which were added. Those in Italics were modified. The rest were left unaltered.
| Class * |
Description |
| |
|
| AxiomSource |
Interface for classes which store axioms (they can be unified with a query) |
| Database |
Implements AxiomSource. Stores axioms found when searching DataStores. |
| DataStore |
Interface for classes that can provide the Database class with information |
| DynamicRule |
The object that is unified against an AxiomSource. |
| Fact |
A Fact's terms are also Facts. example: fact(term,term); |
| LocalDatabase |
Implements DataStore; stores data local to our system not found in WordNet. |
| LogikusFacade |
Class that handles parsing and subroutines used in LogikusMediator. |
| LogikusIDE |
The IDE for the Logikus language, developed by Steven J. Metsker. |
| LogikusMediator |
This class connects the IDE components with their various subroutines. |
| LogikusParser |
This class handles parsing for grammars excepted by the Logikus language. |
| Program |
Original class to implement AxiomSource; now can be loaded from a file. |
| Query |
Object that binds a goal structure with an AxiomSource. |
| Rule |
This corresponds to a Structure with a Horn clause in formal logic. |
| Semantics |
Contains data and methods pertaining to our six chosen word relationships. |
| Structure |
All data entered into Logikus can be represented as a structure. |
| Term |
A Term is an element within a Structure. |
| Wordnet |
The Wordnet class is the DataStore that can query data from WordNet™. |
Table 3. Important classes of ELLES
* It should be noted that the Logikus engine consists of many more classes than are listed here. Listed here are only those objects that will assist in the explanation of the engine's functionality.
Our first modification was to include a new class Database to implement AxiomSource, thereby reducing our reliance on building Programs (a previous idea was to add Facts obtained from the database to the Program text area and parse all the data at once). When taking this first step, we were not yet concerned about how Database would get its axioms, we needed only to assume it would get them from a source or a set of sources, and keep the ability to be unified with a Query object.
Parsing the text in their corresponding text areas in the application forms both the Program and Query objects. The Query object also takes into its constructor a reference to the Program object since it is the axiom source used by the engine. In the original application, parsing is the first step in running a query and receiving a result. The majority of our modifications deal with code that is executed before this parsing step takes place. That way, the application runs in exactly the same manner it would have otherwise, only on a larger set of data. The data it is run on must be determined by information in the query itself, because it is unreasonable to load all data available to the application into it at once. This would cause the engine to run very slowly. Looking at the query before data is accessed is the process to which we have already given the name QueryAnalysis, in section 2.1. It involves a series of steps, divided up among several classes. Because of the necessity that it execute before the parsing of the application's textual data, a series of function calls (control code) have been inserted directly into the LogikusIDE application. Since the LogikusIDE class itself only handles the visual components, the code was actually put in the class LogikusMediator, the backend of the application.
Thus, the second modification was the insertion of control code into LogikusMediator. There are several other classes behind the GUI environment that handle passing data and parsing it, including LogikusParser, and LogikusFacade (which handles error checking). The control code follows this sequence of steps:
- Parse only the Query text area; look inside the resulting Query object to find which functor is used, as well as what terms or variables are specified.
- Analyze these terms and functors so that a list of axioms can be generated, the smallest possible list, that would give the user the "right answer" no matter what the Query structure looks like. In this step of the process, WordNet™ must be queried in order to provide information necessary to building this list. An example of this might be when an "isa(a,b);" structure is found the Query structure. An isa(a,b) query must then find every hypernym of b in WordNet™. We don't know at this point which ones will be used. Because raw data is returned and axioms are then created from this raw data, the axioms may not be completely accurate. So, we must test them again by searching for them.
- Step three assumes that a list of "hypothetical" axioms has been generated. Then they are tested against both DataStores. (Simply, do they exist?)
- Finally, a list of axioms is produced that do exist in the DataStores but we have already determined that no facts other than these could possibly unify with the query. This whole process is simply in order to prevent our query from needing to be unified against every structure in each DataStore.
The Query text area is thus parsed twice. The first time it is parsed, a Query object is not produced. Instead, only a Rule object is produced (which is basically an array of Structures, the first being the head to the Horn clause). That Rule is passed to the Database class where it is used to load appropriate information from the DataStores. As was mentioned, the LogikusMediator class was the ideal place to start this process. It is the class containing actionPerformed() and calls Metsker's conductProof() method after one of the "Prove" buttons is pressed. This is code from conductProof(), which contains our control code for the QueryAnalysis process:
protected void conductProof() {
setComputing(true);
try {
// control code for query analysis and data retreival.
flushProgram();
analyzeQuery();
buildProgram();
// end new code segment.
parseProgramAndQuery();
} catch (Exception e) {
// exception code
}
resultsArea.append(text + "\n"); // ...
}
There is an instance of Program in the LogikusMediator class that appends new axioms to itself during the execution of every query. Thus, it must be refreshed, using flushProgram(), after every new call to conductProof() in order to reduce redundancy in the data. AnalyzeQuery() and buildProgram() are new methods that handle the fetching and collecting of data, respectively. Here is the analyzeQuery() method with some explanation:
protected void analyzeQuery() {
String queryText = queryArea.getText();
// this actually constructs a Rule object...
databaseQuery = LogikusFacade.dbquery(queryText);
// which is used to construct a Database object...
Database temp = new Database(databaseQuery);
// which is appended to the cumulative Database.
database.append(temp);
}
The text from the QueryArea is sent to LogikusFacade to be parsed. This returns a Rule object that is added to the constructor for a new Database object. At every execution, the new Database appends its axioms to the cumulative Database. Every Database object has the ability to look for needed data based on the query (now a Rule structure) that it is given in its constructor. So truthfully the Database class is not set up very much like a database, but that could be done later. It is meant to be the facilitator between a user's query and an efficient means of proving that query against a large source of data provided by the DataStores (recall that DataStore is our abstract interface for classes that feed data to our system).
This sequence diagram shows the transfer of command between classes. Notice that Mediator (short for LogikusMediator) truly mediates between the user interface and the system's functionality:

Fig. 3 - Sequence Diagram
The last step in the control code is buildProgram(). This method takes data returned from the DataStores and combines it with both the user's Program and a set of Rules that is static to the system. In the end, axioms from all of the "AxiomSources" must be relayed into one AxiomSource, namely a Program, which acts as a buffer for axiomatic data.
When the control code finishes execution, all axioms have been collected into one Program, which is unified with the query and the results are printed in the Results window. If no variables were used in the query, the result will either be yes or no (yes for true and no for unprovable). If a variable is entered into the Structure typed in the Query window, then Logikus will find every match for that variable in the Program.
2. 5 Lexical Knowledge Base Interface
Recall that our Lexical Knowledge Base Interface is now called DataStore. Each of the DataStores (WordNet, a LocalDatabase, and possibly others to be added later) needs its own class to store methods relating specifically to its implementation. To access data from WordNet™, the Database class needs an instance of a class that holds JwordNet instructions because the JwordNet utility is the tool we chose for querying the WordNet™ data files. The same is true with the class that handles our local database (our local database is currently a collection of text files. If we chose to implement a real database management system later on, we would simply add a new class that implements DataStore and interacts with a JDBC application.).
Since DataStore is an interface and can't store instance variables, we extended the functionality of the Database class to include holding an instance of every implemented DataStore. Here is a partial UML diagram describing this behavior:
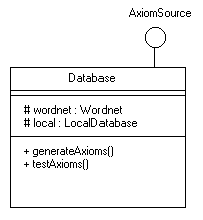
Fig. 4. UML for Database Class
The next two sections describe the DataStores that are currently implemented. The methods listed in the UML diagram are where steps 2 and 3 of the control code sequence (see section 2.4) are executed. These steps correspond to the generateAxioms() and testAxioms() methods, respectively.
2. 6 WordNet™ And The JWordNet Utility
JWordnet is a set of classes written by Oliver Steele, a linguist working on a number of interesting language programs for the computer science department at Brandeis University. The JWordnet source code is available at
http://jwn.sourceforge.net/.
Using the classes provided by JWordnet, any of the information contained within the Wordnet system is available. The Wordnet class used in ELLES directly calls JWordNet functions in order to pull word information out of Wordnet and process it into a string or string array to be returned. The information returned is:
- A word and the gloss (short definition) for each of its senses (a sense is a distinct definition of a word, where the word has more than one distinct definitions or uses)
- The word’s synset (set of close synonyms)
- Pointers to the word’s holonyms, hypernyms, meronyms, by which all of these things can be retrieved
- The word’s lemma
The main classes provided by JWordNet are DictionaryDatabase, IndexWord, and Synset. The important thing to note about these different classes is that objects of these types often contain more information than the name suggests. A DictionaryDatabase object is instantiated to create a pathway to the WordnetTM database. An object of type IndexWord is then created using that Dictionary object. It contains the word and all information relating to it, including multiple definitions, synsets, pointers to its holonyms, meronyms, etc., its part of speech, and so on. Table 4 shows a few examples of the JWordNet classes in action. For more information, see the JavaDoc files that come with JWordNet.
| Code |
Explanation |
| DictionaryDatabase dictionary = new FileBackedDictionary(); |
Creates pathway to WordnetTM. |
IndexWord word = dictionary.lookupIndexWord
(part-of-speech constant, string); |
The IndexWord type stores a word and the word’s related information, which is obtained through the DictionaryDatabase.lookupIndexWord function. Notice that you have to know the part-of-speech of the word you are looking for already (POS.NOUN, POS.VERB). String here is the word you are looking up, say "word." |
| word.getLemma(); |
Returns a the word’s lemma (string representation). |
| word.getPOS().getLabel(); |
Returns a word’s part-of-speech. Add ".getLabel()" to convert it to a string. Otherwise, it returns a constant like those mentioned above. |
| Synset[] sense = word.getSenses(); |
An array of Synset objects stores the synonym sets of the word. |
| sense[i].getDescription(); |
Returns a string representation of the words in the synonym set separated by commas. |
Table 4. Example JWordnet Functions
2. 7 Local Knowledge Base
The local knowledge base (now renamed LocalDatabase) is used for storing noun-verb relationship types that aren’t provided by the WordnetTM system. Its Java class is also an implementation of the DataStore interface. For now the local knowledge base is implemented only as two small ASCII text files, objects.txt and actions.txt. They can contain any number of facts and rules, depending on their functor type. The LocalDatabase class ignores any of the lines of text other than those that represent a Logikus Structure. Its implementation was obviously structured around file I/O.
This DataStore will ultimately be the most important since we will also have the ability to write data back to it. One intention behind the design of ELLES was that the local knowledge base be a full database accessed through JDBC. Then the task of inferencing could be expanded to learning. For this prototype of ELLES however, the text file scheme was implemented instead. See the future recommendations for further discussion of this design issue.
2. 8 Query Analysis Algorithm
Since a large goal for our system was to have it "read" logical goal statements and search through data in order to solve the goal statement, the largest obstacle we encountered was getting the necessary data into a set small enough Logikus could solve it efficiently. The means by which we overcame this obstacle was having it perform a pre-analysis of the goal statement before data entered into the engine. The sub-system responsible for this, we have called it QueryAnalysis, returns all axioms from the DataStores that could possibly be used by the goal statement (or query). Because of the system's rules for defining a "does" query, for the query
does(dog, bark);
to be true, one of two subqueries must be proven true. They are:
- has(has_ability(dog, bark);
- isa(dog, X) AND has_ability(X, bark);
The first subquery unifies completely if the axiom has_ability(dog, bark); is found in the DataStores. Now let us say that the first subquery does not unify (it is not found). The second subquery (isa AND has_ability) continues to execute recursive calls until either both of its structures are proven or it hits a null value. X, in the second subquery above, is unified many times because the Isa rule is defined transitively (A isa B and B isa C, therefore A isa C). The two conditions are that solve an Isa query are:
- hypernym(dog, X);
- hypernym(dog, Y) AND isa(Y, X);
In other words, the engine continues to cycle through similar subqueries, looking at every superordinate of dog, until statement 3 is unified with a value or there are no more values to match with it. Then the engine would use the results from the Isa query to prove the Does query above.
Usually a set of data is given to a logic engine without worrying about what kind of data it is. The engine picks out what it needs. We don't have super-computers available to us, unfortunately, and so we did have to worry about the amount of data coming into our engine. We don't know before the engine runs on a set of data which data will be needed to resolve query. We do know the way the data will be sorted through, however. It follows its own definition (if the query structure is a rule, that is. Facts can be used in queries also, they just don't give results that are as interesting). The basis of QueryAnalysis, therefore, is to "think ahead" and reverse the implications given by the logical rules that make up a specific query.
The code in Database is set up around these four query "configurations" (order of their terms): functor(root_word,Variable), functor(Variable, root_word), functor(root_word, goal_word), and functor(VariableX,VariableY). In most cases, the last configuration is not helpful at all, it will try to unify everything in the DataStores together with everything in the DataStores! If the functor is one of the six rule types from figure 2 in section 2.2, then the results of a query functor(root_word,goal_word) are defined by some combination of searches, based on which rule type the functor is.
The two configurations that have both a root word and a variable are the most straightforward. However, when the functor(Var,root_word) configuration is used, the normal process becomes inverted. The user is now asking "what things have the hypernym X, rather than "what hypernyms does X have?" This is the reason that every fact type has an inverse fact type (except synonym). The inverse fact type for hypernym is hyponym, which searches for the subordinate in a hierarchical organization, rather than the superordinate.
Returning to the application, Database has a getData() method that is passed the functor of the current query, the corresponding fact type or its inverse fact type for that query type, and the root word of the query. From this, it loops through the available DataStores looking for axioms that could possibly unify with the query. Here is psuedo-code for this process:
Create String[] construct;
Create Vector findResults;
Create DataStore[] sources = {Wordnet, LocalDatabase};
// for each DataStore...
for (0 to sources.length) {
// find all lexems of given fact type...
//if requested type exists...
if(factType > 0) {
construct = sources[d].find(root_word,factType);
// add facts directly to database...
for(0 to construct.length) {
// get rid of empty queries...
if(construct[c] == null) {break;}
else {
--------------->
// order depends on main fact type...
if(factType == Semantics.getMainQueryType(factType));
addAxiom(new Fact(functor,lexem,construct[c]));
else
addAxiom(new Fact(functor,construct[c],lexem));
--------------->
// add find results to a vector...
findResults.addElement(construct[c]);
} } } }
return findResults;
Find() is the most important step here. This is where the DataStore interface comes into use. Every DataStore must implement find().
For example, if we get a query that looks like hypernym(dog,X), we first determine that we should search for hypernyms of dog, rather than hyponyms of dog. The first DataStore would return an array of words that are hypernyms of dog, and all synonyms of those words. The second DataStore, in this case, would not return anything because for now only Facts of types has_ability and has_object are stored in the text files. Finally, New axioms are constructed and added to a Vector by means of the private method addHypotheticalAxiom().
If the query had been of a rule type rather than a fact type, the difference is that we might have to run this algorithm several times, perhaps looking for different fact types at each step. The does rule first runs this algorithm to find all hypernyms of the root word, then it looks for has_ability facts that have the correct matching term with every word generated in the first search.
The other method that each DataStore must implement is exists(). This method actually looks for each of the created axioms in each DataStore, to make sure it does exist. Once axioms are tested this way, they are added to another Vector, simply called axioms. This final set of axioms works in the Database class in the same way it does in the Program class. Both implement the AxiomSource and so their data is compatible. This is why it is so easy to combine the Database axioms with the user's program during the buildProgram() stage. The code is simply program.append(database).
Design Methodology
The design process followed an iterative approach that began by answering these questions in order: What is the problem the program will solve? What are the best tools for achieving that objective? What are the parts of the program? How will they interact with each other? Are the tools well-suited to providing the functionality of these parts? Will the program solve the problem with these parts?
The last question is an evaluation of our success and coincides with the first question in the list. By answering each of these questions in order, the design emerges, is evaluated and improved upon, and emerges again. This creates a design cycle that is followed again and again, each time producing a better design than before.
The final product of the many design cycles are what make up the performance specifications listed above. Obviously the design process was not complete after just one cycle, but took many. The first design cycle yielded the following results. The problem was stated as the inability of software to grasp the meaning of the English language and the need for an underlying system for processing that meaning. The aim of the program, then, as stated in our proposal, was to serve as "a bridge between natural language logical instructions that is accessible to the broad range of data processing applications used today."

Fig. 5. The initial component diagram
The parts of the program in this initial design cycle were represented by the illustration in Figure 1. One necessary piece of the program from the beginning was a component for storing descriptive data about words and grammars. XML was targeted as a tool that could best provide this component. The idea was to create a markup language that could markup words and sentences in order to give the expert system all of the data it needed to process a sentence or word.
The "XML Data (Dictionary)" component of figure 1 was meant to store information about a specified domain of the English language, meaning a set of words pertaining to some related set of objects in the real world. Proposed domains were the Peanuts cartoons, things found around the house, and the game Clue. The proposed domains were all rather limited because of time. It was necessary to devote time to developing the inferencing engine rather than populating a large data set.
In this rather simple conception of the program, there are only two main parts: the inferencing engine and the data set (XML "Dictionary"). Everything else were helper applications to those pieces. The XML parser seen in Figure 1 is the necessary bridge between the XML data (dictionary) and the inferencing engine. The XML data (memory) component was intended as a temporary storage area for the inferencing engine, as it was anticipated that a large amount of data mining would be occurring as the inferencing engine tried to prove a query.
The next design cycle asked more questions about the necessary pieces of the program. For one thing, no mention was made in Figure 1 about the user interface. For another, similar programs, like Cyc, have an output component—a place to store proven facts and theorems after the initial data has been processed. The idea is that the program begins to build up its own knowledge base after it has enough conversations. Indeed, the ability to learn is actually cited as one of the pieces of an expert system. With this in mind, the second design cycle produced the following diagram, which planned for including components that allowed the program to learn.

Fig. 6. Component Diagram With Output Dictionary
One implied but not stated thing about this diagram is that the "Output Dictionary Document" is the same as the "Input Dictionary Document." The data source in this diagram is really the "Root Dictionary." Tracing the flow of the program using this document, the following steps would take place as the user used the program:
- The user enters a natural language query at "User Input."
- The syntax interpreter / formulator translates the user input into something usable by the application front end, which is really just a fancy way to say modulator, or the portion of the program that passes things back and forth between the different components.
- The application front end receives the translated query and together with the logic engine, decides what information it will need to answer the query. Searches are first made of the Input Dictionary Document to see if the program has already dealt with a query similar to or the same as this query. If not, additional information is pulled from the root dictionary if it exists. All of this stuff is stored in the registry.
- Finally, once all the information has been collected to the registry, the logic engine determines the answer to the query and it is sent to the screen for the user to see. If the query is something new, the application front end also sends the information through the XML encoder where it is stored for future use in the Output Dictionary Document.
Note that the design at this point in time was already becoming rather complex in terms of the application front end. The number of different components that the application front end dealt with and the number of responsibilities it had were large, and it wasn’t known at this time whether or not the design in question was actually a feasible design.
The third design cycle was very critical. It was determined that there were serious deficiencies in the design, mostly because the domain of language had to be very limited in size. The XML data, whether as a dictionary or memory component, would be stored in a plain-text file under the scheme in question, which meant that a) it would take up a large volume of storage, b) it would be a very slow program because searches would depend on reading lines from the disk, and c) as mentioned earlier the data set would be limited, and in the end, this design would be inflexible if a future user wanted to have a larger data set (who wants a 7MB text file?).
These considerations led to searching out alternatives to a data set stored in a plain-text file. One simple alternative is some combination of compression and indexing on a file. But then, why not just use a full-scale database? This would solve most of the problems, but also would mean a higher amount of maintenance, and would still mean that the user would have to populate the data set, effectively turning one project into two.
One potentially promising solution was the idea of using an online dictionary as a data source. Querying an online dictionary would perhaps be faster than searching through a large text file, and also would eliminate the need to create a data set and then maintain it. Using an online dictionary also means the data source is self-contained and does not need to be distributed with the program, but is readily available to anyone. After deciding that this was probably the best available solution, the next design cycle took this into account.
The immediate consequence of eliminating the local file storage for the data source was that the XML markup language was no longer needed for the root dictionary. That meant that it could be less broad in its scope. Recall that earlier the markup language was intended as a general descriptor of English language sentences and the meaning of words (an example given in an early report are shown in figure 7). Now the markup language had to deal only with describing facts or theorems that had already been determined by the logic engine based on previous queries.
<Noun type="abstract" term="musician">
<Parent>person</Parent>
<Parent>occupation</Parent>
<Def>play instrument</Def>
</Noun>
Fig. 7. An Early Example of the XML Markup Language
With this in mind the design cycle began again. After asking the question, "Are the tools well-suited to their task?" it became difficult to justify using XML. The markup language, if created, would have a very limited number of tags. The main issue was the data that being stored. If divided into a table, this data was only going to have two parts: what kind of relationship it implied and what words that relationship was between. For instance, if it was going to store the fact that a musician is a person who plays an instrument, the relationship is a verb relationship between musician and instrument, and the verb is play. A full markup isn’t needed for this kind of data storage. In the end, in fact, an example like this was found to be stored rather simply as two facts in a logic program ("has_ability(musician, play)" and "has_object(play, instrument)"). At this point in the design, though, such specifics had not been discussed.
After much consideration, the decision was made to continue the role of XML in the design. XML wasn’t useful for the Output Dictionary, but it was suggested that XML could be ideally suited for providing heuristics about the English language, in the form of lexical relationships and grammar templates. The role had shifted from direct data description to syntactical models that would provide the syntax interpreter with the rules for how it would go about doing its job. In some way the XML had returned to its original role in the design.
XML wasn’t the only major design consideration during this cycle. Also under continued scrutiny was the role of the online dictionary. The Merriam-Webster dictionary at http://www.m-w.com looked ideal, because it provided a number of helpful features other dictionaries did not. Parsing this information was going to be troublesome, though. Most definitions returned from such a dictionary are long sentences. Writing a program to split the definitions apart, grab the relevant sentences, the relevant parts of sentences, and determine related words is an ambitious project all on its own. There wasn’t going to be time to accomplish this task.
Eventually, a major breakthrough came during our research when a posting on alt.comp.ai.nat-lang made reference to a system called WordnetTM. WordnetTM was perfect for the project. It was based on language research and organized according to what that research revealed about human cognitive language organization. Not only did Wordnet provide a data source, it also exampled a good set of necessary lexical relations: synonyms, hyponyms, meronyms, hypernyms, hyponyms, and so on. These concepts slowly became the basis for our program.

Fig. 8. Third Component Diagram
Figure 9 shows the component diagram after this design cycle. Now there were a number of components added or renamed. Wordnet was now the data source rather than the "Input Dictionary." And since version 1.6 of Wordnet was online at http://www.cogsci.princeton.edu/~wn/, it served the same function as an online dictionary. Under this component diagram, a component called the lexical assertion algorithm crawled Wordnet much like a web spider or robot crawls the web. What the lexical assertion algorithm was to look for was any provable relationship between words found in Wordnet. The output form component was meant to be a check on the results returned from the lexical assertion algorithm, in the case that the lexical assertion algorithm returned answers that weren’t necessarily true all the time.
The XML grammar and lexical relationship descriptions are depicted in the diagram as communicating with "main," or what we formerly referred to as the "application front end." In reality, the plan was that they would be loaded to help both the interpreter component and the translation of user queries. Finally, there are still plans in this phase of the design to include a full system for processing natural language queries.
The final design cycle was less concerned with modifying the pieces of the design, but with what pieces to implement, given the time remaining and a few other minor questions of how the program as a whole was to function. Also, a better understanding of logic language programming revealed that XML was no longer needed for the heuristics, or the grammar rules and lexical relationships, because logic programming provides an almost natural model for describing the lexical relationship between words. This final design cycle occurred just before coding began in late March.
Many components were dropped for this final component diagram. Most notable is the natural language query processing components. For time’s sake, this will have to be added later. Users of this program currently have the option of a limited set of query structures that should be easily translatable to natural language later on. These are discussed in the specifications. Also absent from this phase of the design is the ability for the program to learn from one session to the next, the output dictionary. While there is a set of components in this diagram that allows the program to accumulate proven queries from session to session, it has not yet been implemented. For the time being the only learning the program does is during the session. After the clear button is pressed, the program resets to an initial state.

Fig. 9. Final Component Diagram.
KB stands for knowledge base, LKB for local knowledge base.
This component diagram doesn’t fully illustrate the parts of the program, but rather groups similar parts into single components. Again there is a central moderator, the "environment" component, that oversees the entire program and passes necessary information back and forth between the different components. The logic engine is also the same as in past diagrams.
The user interface here is broken up more or less as it is presented to the user in the final program. There is a query window and a results window. The structures component is the place where rules and facts are stored as required by Logikus.
Finally, the LKB interface in figure 9, implemented as a Java Interface object, allows the program access to classes such as Wordnet and LocalDatabase that provide further access to data sources. LocalDatabase is a plain text file holding verb-noun relationships not found in Wordnet. Wordnet makes use of Oliver Steele’s JWordnet classes to return string arrays of hypernyms, holonyms, meronyms, and so on. For more information on these two parts of the design, see sections 2.6 and 2.7.
Another important note about this final phase of the design is the abandonment of the lexical assertion algorithm. Further experience with WordnetTM revealed that it was an efficient system, and that the process of requesting and receiving data from the system through JWordnet was fast and seamless. Moreover the translation from string to Logikus structure was natural, given that the Logikus IDE already provided classes for parsing and converting user-input programs. These two reasons led to the conclusion (which was later beared out in testing) that the program could query Wordnet, parse the data, and translate it into Logikus fact structures in a negligible amount of time.
Given the efficiency of this on-the-fly WordnetTM data to Logikus structures processing, it was apparent that the lexical assertion algorithm could be replaced with an algorithm meant to dynamically create the necessary facts and rules for query unification, at the time of the query. Rather than have a type of WordnetTM-walking spider that has, at some time in the past, produced a set of rules and facts the user is able to query against, ELLES would now have the capability to start with no rules and facts at all, and request only those it needed to prove the given query at the given time. This query analysis algorithm, which is discussed further in section 2.8, eventually did replace the lexical assertion algorithm. It is a core function of the final design.
Results
To operate ELLES, a user must install WordNet™ locally, then run the application from the Elles v1 folder. If done at the command prompt from this directory, he or she would type: java.exe sjm.examples.logic.LogikusIde.
The user then has the option to load one of the text programs. This will simply load a text file into the Program text area. A user can write a program in a text file and load it each time, as to not have to type a program again and again. The provided example text programs are aliens, widgets, and semantics (the set of rules as the application uses behind the scenes).
The user can add Facts and Rules to the Program window. Also, axioms produced by running queries are kept in memory (they accumulate) so that more complex queries can be executed by writing them in a step by step fashion. A user can even run more than one query at once, if the structures are separated by commas. This works just like a rule does; the first structure is the head and all others must be true for the first one to be true (which makes the whole query true). The result is the same as ANDing the results of the multiple queries together.
A query that a user might run is: does(bird,fly).
Answering queries (otherwise called proving goal statements) was the aim of the program. Table 5 goes over the six queries and their mutations, describing what will be returned for each query.
| Query Type |
Description |
syn(X,Y); |
X and Y must be nouns. X and Y cannot both be variables.
Returns yes if X and Y are synonyms, no if not. |
isa(X, Y); |
X and Y must be nouns.
X and Y cannot both be variables.
Returns yes if X is a Y, no if not. The requirement for X to be a Y is that X is a kind of Y, although it is not necessary that the relationship is immediate. For example, a dog is a mammal, even though the immediate classification above dog is canine. |
hasa(X, Y); |
X and Y must be nouns.
X and Y cannot both be variables.
At least one of the two (X or Y) must be a string constant.
If both X and Y are string constants, the program returns yes if X has a part Y, no if not.
If Y is the string constant, a list of objects that have Y as their part will be returned.
If X is the string constant, a list of all the objects that are parts of X will be returned. |
does(X,Y); |
X must be a noun and Y must be a verb.
X and Y cannot both be variables.
At least one of the two must be a string constant.
If both X and Y are string constants, the program returns yes if X the ability to Y, no if not.
If Y is the string constant, a list of objects that have the ability to Y will be returned.
If X is the string constant, a list of all the abilities of X will be returned |
does_to(X,Y) |
X must be a verb and Y must be a noun (direct object). X and Y cannot both be variables.
At least one of the two must be a string constant.
If both X and Y are string constants, the program returns yes if X can be applied to Y (if an agent can X a Y), no if not.
If Y is the string constant, a list of verbs that can X Y will be returned.
If X is the string constant, a list of all the possible direct objects of X will be returned |
case(W,X,Y) |
W must be a known, X a verb, and Y a noun.
W, X and Y cannot all be variables.
The program returns yes if W can do X to Y. Otherwise, it returns no. |
Table 5. Query syntax.
Cost Analysis
All of the tools used in completing this project are free with the exception of the Logikus software provided with the book Building Parsers With Java, by Stephen J. Metsker. Although the code is open source, and is provided with the book to be used by computing professionals who wish to write their own programming languages, it is available only on the included CD. The book is published by Addison-Wesley and has a suggested retail of $39.95.
Other tools used were Wordnet, JWordnet, and Java. The WordnetTM binary and documentation are available for download at http://www.cogsci.princeton.edu/~wn. JWordNet is available from http://jwn.sourceforge.net. The Java 2 SDK, version 1.3.1 was used to write the code for ELLES. It is available from Sun Microsystems at http://java.sun.com.
Conclusions
The results obtained from tests of the program show that ELLES mostly behaves according to the specifications. All six of the implemented queries work properly, and used in combination with each other, can be very powerful. It is handy that the program saves all results from past queries until the "Clear Program" button is pressed. This functionality allows queries to become more complex if executed in the proper order.
ELLES’ speed is also impressive. Thanks to the query analysis algorithm there is not a large amount of time that passes between the time the prove button is pressed and a result is returned. Even though the query analysis was expected to increase the speed of the proof process by narrowing the amount of facts pulled from the data sources, it was still impressive to see that even large queries, like those that return lists, are executed almost immediately.
Some behavior wasn’t expected, but was easily explainable as the result of characteristics of the knowledge bases. For instance, because WordNetTM is so extensive, and because ELLES currently doesn’t have a system for keeping senses apart from each other, some queries unify that the user thinks should not. For instance, because there is an island called the "Isle of Man" the query "isa(man, island)" returns a yes, once and for all disproving the classic statement "No man is an island."
ELLES answers all queries as it should. Test queries have consisted of false and true queries and ELLES has answered correctly each time. In conclusion, ELLES performs well and has met the performance specifications.
Recommendations
- One of the next steps that should be taken is to expand the number of word relationships for verbs and also for other parts of speech. WordNet™ implements a few of these, the rest (of a source of this data) would have to be entered by hand.
- It will be a small step to make our query text area into a script analyzer, and finally into a natural language processor. Right now there is one query that already represents a simple sentence (case), and many more could quickly be added and experimented with.
- To use a system like ours effectively, there must be some differentiation between word senses. Ideally, there should be a source of probability data so that when the system has to guess as which sense of a word it is looking at, it's guess will not be completely in the dark.
- Other additions might be the full knowledge base, knowledge base editor, and the explanation subsystem.
- Works Cited
- Connors, Robert. Lunsford, Andrea. The New St. Martin's Handbook. Boston: Bedford, 1999.
- Metsker, Steven J. Building Parsers with Java. Boston: Addison-Wesley, 2001.
- Miller, George A., et. Al. "Five Papers on Wordnet." Adobe Acrobat Download. http://www.cogsci.princeton.edu/~wn/index.shtml.
- Nilsson, Nils J. Principles of Artificial Intelligence. Palo Alto, CA: Tioga Publishing Co., 1980.
- Sebasta, Robert W. Concepts Of Programming Languages. 4th Ed. Reading, Massachussetts: Addison Wesley Longman, 1999.
- Steele, Oliver. JWordnet. Download at http://jwn.sourceforge.net.
- Appendices
9.1 Appendix A: Glossary of Terms
Axiom: A statement that can be written in formal logic. In Logikus, they have two forms, facts and rules. Rules contain the implication character ':-' and the implication is true only when the beginning structure is true.
Java: A powerful object-oriented, platform-independent programming language developed by Sun Microsystems.
Lexicon: A set of lexems, a dictionary.
Logikus: A logic language developed by John Metsker for his book, Building Parsers with Java.
Prolog: The standard language used for artificial intelligence applications. It is based on the formal rules of logic and predicate calculus.
Semantics: The study of meaning in language.
Syntax: Structural considerations of language; those rules that specify how words fit together to form sentences.
Wordnet: A lexical database of the English language developed by the Cognitive Science Laboratory at Princeton University. It is based on psycholinguistic theories of human lexical memory. For more information, see http://www.cogsci.princeton.edu/~wn/index.shtml.
XML: An acronym for Extensible Markup Language. XML was developed by the Worldwide Web Consortium and "describes a class of data objects called XML Documents and partially describes the behavior of computer programs which process them" (Extensible Markup Language 1.0 Second Edition W3C Recommendations, found at http://www.w3.org/TR/REC-xml).
9.2 Appendix B: Lexical Relationship Definitions
Description |
Relationship |
Meaning |
Hierarchical |
hypernym * |
Noun(A) isa Noun(X) |
hyponym * |
Noun(X) isa Noun(A) |
Logical |
equals |
General(A) = General(X) |
not |
General(A) = ~(General(X)) |
Synonym/ Antonym |
antonym * |
General(A) hasa opposite (General(X)) |
synonym * |
General(A) and General(X) elements of synset S |
Association |
meronym * |
Noun(A) hasa component (Noun(X)) |
holonym * |
Noun(X) hasa component (Noun(A)) |
Direct Action |
has_ability |
Noun(A) hasa ability (Verb(X)) |
has_agent |
Noun(X) hasa ability (Verb(A)) |
Indirect Action |
has_object |
Noun(A) hasa action (Verb(X)) |
has_action |
Noun(X) hasa action (Verb(A)) |
Transformations |
has_baseform |
General(A) hasa baseform (General(X)) |
has_plural |
General(A) hasa plural (General(X)) |
Tree Relationships |
sister_to * |
(Noun(A) & Noun(Y)) isa Noun(X) |
root_of * |
(Noun(A) isa "thing")&(Noun(A) isa ancestor(Noun(X))) |
descendent_of * |
Noun(A) isa (descendent (Noun(X)) | Noun(X)) |
ancestor_of * |
Noun(X) isa (descendent (Noun(A)) | Noun(A)) |
Contextual |
has_context |
(General(A) | Relation(A)) hasa context (Phrase(X)) |
pertains_to |
(Noun(A) | Relation(A)) hasa relationship (Noun(X)) |
* Implemented in WordNet™
9.4 Appendix C: System Rules
Rule Structures |
Description |
syn(X,Y):- synonym(X,Y); syn(X,Y):- synonym(Y,X); |
A synonym relationship is reflexive. In WordNet™'s model for word relationships, groups of words that are synonyms of each other are called synsets. The words in this synset are senses that are equivalent, though they have different lemmas. |
isa(X,Y):- syn(X,Y); isa(X,Y):- hypernym(X,Y); isa(X,Y):- hypernym(X,Z), isa(Z,Y); |
The isa relationship is used for traversing WordNet™'s noun inheritance structure. A canary isa animal. Because isa is transitive, canary also isa animal, and also any superordinates of animal. |
does(X,Y):- has_ability(X,Y); does(X,Y):- isa(X,Z),has_ability(Z,Y); |
Does is the set of rules that allows abilities to be transitive. If a bird can fly, then a canary can fly. |
does_to(X,Y):- has_object(X,Y); does_to (X,Y):- isa(Y,Z),has_object(X,Z); does_to (X,Y):- connected(Y,Z), has_object(X,Z); |
Transitive in this sense refers to verb transitivity. If a verb can have a certain object, then it is transitive to that object. |
case(W,X,Y):- does(W,X), does_to (X,Y); |
This is the simplest sentence query. It is true for all combinations of does() and transitive() queries that share their verb in common. |
part_of(X,Y):- holonym(X,Y); |
This is a simple holonym query that can be expanded |
hasa(X,Y):- meronym(X,Y); |
This is a simple meronym query for testing |
connected(X,Y):- joined(X,Y); connected(X,Y):- joined(Y,X); |
Connected is the reflexive modifier for objects that are joined together in some way. |
9.5 Appendix D: System Facts
Fact type |
Description |
Example |
synonym |
"is" relationship |
car, automobile |
hypernym |
parent-child relationship |
car -- vehicle |
meronym |
"parts of" relationship |
car -- wheel, engine |
holonym |
"is part of" relationship |
boat -- fleet |
has_ability |
"has the ability to" relationship |
car -- run, turn |
has_object |
"what you can do to it" relationship |
start, fix -- car |
|